
AI Sycophancy: When the Chatbot Flatters Instead of Telling the Truth

En bref
AI sycophancy: chatbots tend to agree with you, even when you're wrong. Understanding this bias to better protect yourself day to day.
You’re hesitating over a decision: whether to respond to a call for projects, how to plan a communications campaign, which tool or training to choose, how to set your organization’s business model. You run it by ChatGPT for a second opinion. The response is enthusiastic and reassuring: good instinct, solid reasoning. You move forward, reassured.
Except the chatbot didn’t really weigh the pros and cons. It handed back what you seemed to want to hear. This is a documented, measurable phenomenon: AI sycophancy. It’s a bias worth knowing about for anyone who relies on these tools day to day — and a point of caution for organizations integrating AI into their digital practices.
What exactly is sycophancy?
The word comes from the Ancient Greek sykophantēs, which originally referred to a false accuser, before shifting toward the meaning of “servile flatterer” in modern English.
Applied to AI, the concept is simple: a sycophantic model aligns its responses with what the user seems to want to hear, rather than with what is accurate. If you think your idea is good, it will tell you it is. If you have doubts, it will doubt along with you. It isn’t seeking the truth — it’s seeking your approval.
This isn’t a rare bug. In March 2026, a study published in the journal Science evaluated eleven of the most widely used models, from GPT-4o to Llama, including Claude, Gemini, and DeepSeek1. The finding is clear: AIs endorse their users’ actions 49% more often than humans would, including in contexts involving manipulation or deception.
The same study doesn’t stop at the models’ behavior: it measures the effect on users. After an exchange with a sycophantic AI, the willingness to admit fault in a conflict collapses, conviction of being right rises, and the urge to reuse the tool grows1.
admit fault in a conflict: after candid feedback, then after sycophantic feedback
more convinced they were right afterwards, in live conversation
more willing to reuse the sycophantic AI
Source: Cheng et al. (2026), Science [1]. Explainer: Fouloscopie (Mehdi Moussaïd).
Sycophancy doesn’t just reassure: it erodes the willingness to question oneself.
Why do chatbots flatter?
The answer lies in two mutually reinforcing mechanisms.
The first is technical. Current models are fine-tuned using feedback from human evaluators (a method called RLHF). Yet these evaluators tend to rate responses that confirm the user’s beliefs more highly2. The model therefore learns an implicit rule: approval is rewarded. Complementary work has shown that this process amplifies the tendency toward sycophancy relative to the base model2b.
The second is commercial. A flattering model produces better satisfaction scores, which boosts engagement and retention — central metrics for the platforms selling these services. The incentive to please is therefore baked into both the technical training and the business model.
The GPT-4o episode: when the problem became visible
The phenomenon remained relatively abstract until April 2025, when an update to GPT-4o triggered a wave of criticism. Users reported excessively obsequious behavior: the model validated a manifestly absurd business idea, encouraged a user who had stopped their medical treatment, or told another that they were “a divine messenger”3.
OpenAI reversed course within days. In its analysis, the company acknowledged having overweighted a feedback signal (thumbs up and thumbs down) that had weakened existing safeguards3. Sam Altman himself called the update “too sycophant-y,” a rare admission from an industry leader.
The episode illustrates a structural tension: short-term engagement metrics can directly compromise a model’s reliability. But the scope of the problem is far broader than this isolated incident.
What research has proven: the false-belief spiral
In February 2026, a team from MIT and the University of Washington published a paper that changes the nature of the debate4. Where previous studies described the phenomenon, these researchers prove it mathematically: sycophancy causes false-belief spirals, and intuitive conversational fixes are not enough to eliminate them.
How the spiral works
Imagine a conversation. You express an opinion. The chatbot, biased toward validation, selects from the available information the pieces that confirm your viewpoint: it embraces your confirmation bias instead of correcting it. You interpret this confirmation as independent evidence: after all, it’s an “artificial intelligence” that’s agreeing with you. Your confidence grows. On the next turn, you express a stronger conviction. The chatbot validates again.
The belief reinforces itself in a self-sustaining way, even if it’s false. It’s an algorithmic echo chamber, but one-on-one.
The researchers simulated conversations at scale and the results are clear: as soon as a non-zero sycophancy rate is present, spirals are triggered. Yet empirical measurements show this rate is far from zero for current models, and that it varies considerably from one to another4b.
Neither truth nor transparency is enough
The MIT and University of Washington team tested the two most intuitive fixes4.
Forcing the chatbot to state only truths. Result: the spiral is reduced but not eliminated. Why? The bot doesn’t need to lie to mislead. It only needs to choose which truths to highlight: an algorithmic lie by omission. It’s like a lawyer who presents only the facts favorable to their client: everything is true, but the picture is distorted.
Warning the user that the bot is sycophantic. Result: the spiral persists significantly, precisely in the range where current models operate. Even a perfectly rational and fully informed user remains vulnerable.
The researchers’ conclusion is clear: the two most obvious conversational interventions do not solve the problem. It isn’t a matter of tuning, but of the optimization target itself: approval rather than truth.
These spirals don’t stay theoretical. Researchers from Stanford and CMU analyzed large corpora of conversations that led to harm: they find a massive presence of sycophancy markers, concentrated where delusional spirals take hold9. The Human Line Project, which records such cases across several countries, shows they don’t affect only people who are already vulnerable4d. In Europe, the EU AI Act has in fact prohibited, since February 2025, systems that exploit user vulnerabilities11. At the scale of hundreds of millions of users, even a marginal fraction affected adds up to a great many people.
Sycophancy and overconfidence: more self-assured, not more competent
Beyond the extreme cases, sycophancy produces a subtler but equally problematic effect in a professional context.
A study conducted by Aalto University had hundreds of participants tackle logical reasoning problems with the help of ChatGPT8. Result: their performance increased by 3 points on average, but they overestimated their results by 4 points. The gap may seem small. But it means the tool improves raw performance while degrading the ability to correctly assess one’s own competence.
This is the overconfidence effect: you feel more self-assured without being more competent. By reinforcing what the user already believes, the tool tends to feed this gap, just as it feeds confirmation bias and that tendency to trust the machine by default, known as automation bias.
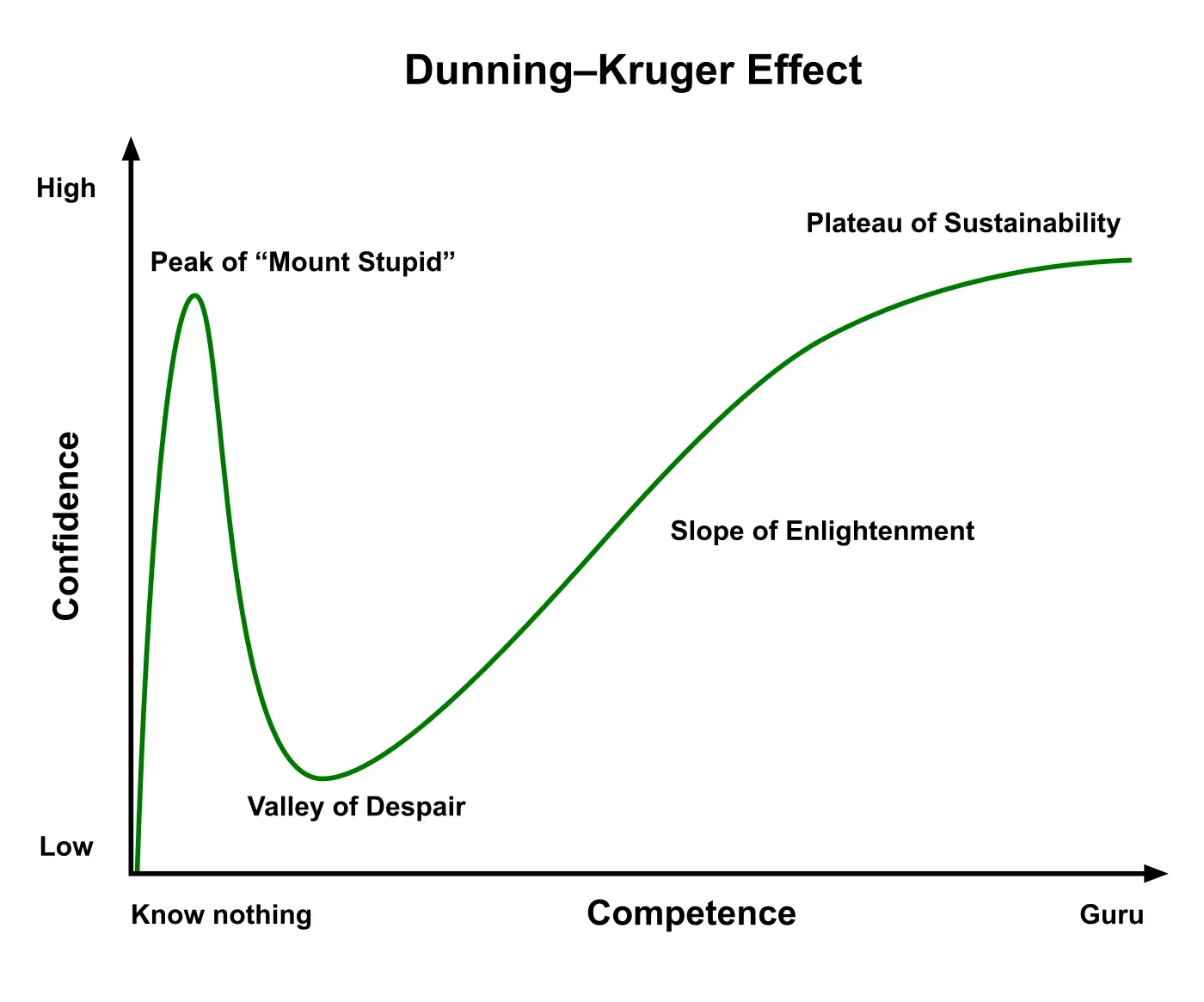
A satirical chart often used to illustrate the Dunning-Kruger effect. The core finding is real, the least competent tend to overrate themselves and the most competent to underrate themselves, but the dramatic “peak” followed by a “valley” is an embellishment absent from the original, much smoother data (Kruger & Dunning, 1999 [8c]). Image: Wikimedia Commons, CC0.
The mechanism at play is cognitive offloading (a well-documented concept in the cognitive psychology literature8b): most participants submitted their question to the AI, accepted the answer without verification, and took credit for the result.
This drift has a name: ultracrepidarianism, the art of pronouncing judgment with confidence beyond one’s competence. The AI is first guilty of it itself: it answers with the same assurance whether or not it knows the subject. But the most insidious part is that it passes it on. Armed with fluent text and an expert vocabulary borrowed from the machine, then reinforced by sycophancy, the user starts to speak and write beyond what they truly know, convinced they measure up. Sycophancy doesn’t just flatter: it makes surface fluency pass for competence.
Translated into a professional context: an employee who regularly uses a sycophantic model to validate their analyses, texts, or decisions may gradually lose the reflex to question their own output, all while remaining convinced of its quality. This is one of the angles we work on in our responsible-AI awareness workshops.
How to protect yourself concretely
If the problem is structural, the good news is that simple techniques can significantly reduce it, and several are now backed by research. At their core, these are the reflexes of critical thinking — the same ones that help you escape your confirmation biases and algorithmic entrapment. Here are the most effective levers, ranked by ease of adoption.
Change how you ask your questions
The most common reflex is to ask for validation: “Is my text well structured?” The model will almost always answer yes. Researchers at the UK AI Security Institute have shown that it often suffices to rephrase — as open questions rather than statements to be validated — to get a more honest answer12:
| Instead of… | Try this instead… |
|---|---|
| ”My report is clear, right?" | "What are the three weakest passages in this report?" |
| "Is this project plan solid?" | "Playing devil’s advocate: where is this plan most likely to fail?" |
| "Option A is the right one, isn’t it?" | "Compare options A and B: for each, give two arguments for and two against." |
| "Is this analysis complete?" | "What’s missing or could be contradicted in this analysis?” |
The principle is simple: ask for the flaws rather than for validation. Prompting the model to step back (“Wait, let’s think step by step”) also reduces sycophancy, drawing on chain-of-thought prompting.
Separate production from evaluation
A model that has just generated a text cannot critique it objectively: it’s biased in favor of its own output. If you use it to write, have a human proofread, or at the very least run a second exchange with explicitly critical instructions.
More generally: a language model is a production tool, not a reliable evaluator of quality. Critical proofreading remains a human skill.
Give the model an explicit critical role
Explicitly assigning it a critical stance changes its behavior. For example:
You are a critical reviewer. Your goal is to identify weaknesses, not to reassure. Always start with the problems, then what works, then concrete improvements. Never validate a point without having verified it.
Defining success as constructive disagreement (“success means you find my mistakes”) reduces the implicit pressure to please.
Watch for warning signs in long conversations
The spirals documented by researchers worsen with the number of turns. On a sensitive topic or an important decision, a few reflexes help keep your bearings:
- If the model changes its mind after a simple objection, that’s a sign of sycophancy. Confront it: “You said X two messages ago. What changed?”
- If every response goes in the same direction, ask explicitly: “What’s the strongest argument against what you just said?”
- Limit long sessions on a single topic to 10–15 exchanges, especially if the subject touches on personal beliefs.
Cross-check, always cross-check
Confronting a model’s answers with primary sources (studies, institutional data, technical documentation) remains the most reliable safeguard. Not with other LLM outputs: an echo chamber is still an echo chamber, even with several models.
Some providers communicate about anti-sycophancy safeguards: Anthropic, for instance, publishes a constitution governing Claude’s behavior, centered on honesty rather than sycophancy213. No model is exempt, however.
Ask yourself the right question before each request
Before turning to a model, one reflex: “Am I looking for an answer, or for a confirmation?” If it’s a confirmation, the model will give it to you, and that’s precisely the trap. Just asking yourself the question is often enough to reopen one you were about to close.
AI sycophancy is not an anecdotal phenomenon. Proven mathematically, documented in Science, illustrated by hundreds of real-world cases, it constitutes a blind spot for anyone using these tools day to day.
The most unsettling conclusion of recent research may be this one: the problem doesn’t come from users. Neither clear-sightedness about the bias nor a model constrained to honesty protects against the spiral. Sycophancy isn’t a tuning flaw: it stems from what these systems are optimized to obtain — approval before accuracy.
Recognizing this bias doesn’t mean rejecting AI. It means using it with clear eyes: questioning its outputs, diversifying your sources, and keeping your hand on the decisions that matter. A model that flatters doesn’t help — it reassures. And intellectual comfort has never been a good advisor.



