
Sycophantie IA : quand le chatbot flatte au lieu de dire vrai

En bref
Sycophantie IA : les chatbots ont tendance à vous donner raison, même quand vous avez tort. Comprendre ce biais pour mieux s'en protéger au quotidien.
Vous hésitez sur une décision : répondre à un appel à projets, planifier une campagne, fixer vos tarifs, choisir entre deux prestataires. Vous exposez vos options à ChatGPT pour avoir un avis. La réponse est enthousiaste et vous conforte : bonne intuition, raisonnement solide. Vous avancez, rassuré.
Sauf que le chatbot n’a pas vraiment pesé le pour et le contre. Il vous a renvoyé ce que vous sembliez vouloir entendre. C’est un phénomène documenté et mesurable : la sycophantie IA. Un biais utile à connaître pour quiconque s’appuie sur ces outils au quotidien, et un point de vigilance pour les organisations qui intègrent l’IA dans leurs pratiques numériques.
Qu’est-ce que la sycophantie, exactement ?
Le mot vient du grec ancien sykophantēs, qui désignait à l’origine un faux accusateur, avant de glisser vers le sens de « flatteur servile » en anglais moderne.
Appliqué à l’IA, le concept est simple : un modèle sycophante aligne ses réponses sur ce que l’utilisateur semble vouloir entendre, plutôt que sur ce qui est exact. Si vous pensez que votre idée est bonne, il vous dira qu’elle l’est. Si vous doutez, il doutera avec vous. Il ne cherche pas la vérité — il cherche votre approbation.
Ce n’est pas un bug rare. En mars 2026, une étude publiée dans la revue Science a évalué onze des modèles les plus utilisés, de GPT-4o à Llama en passant par Claude, Gemini et DeepSeek1. Le constat est net : les IA approuvent les actions de leurs utilisateurs 49 % plus souvent que ne le feraient des humains, y compris dans des contextes impliquant manipulation ou tromperie.
La même étude ne s’arrête pas au comportement des modèles : elle mesure l’effet sur les utilisateurs. Après un échange avec une IA complaisante, la propension à reconnaître ses torts dans un conflit s’effondre, la conviction d’avoir raison grimpe, et l’envie de réutiliser l’outil augmente1.
reconnaissent leurs torts dans un conflit : après un avis franc, puis après un avis complaisant
plus convaincus d’avoir raison après l’échange, en conversation réelle
plus enclins à vouloir réutiliser l’IA complaisante
Source : Cheng et al. (2026), Science [1]. Vulgarisation : Fouloscopie (Mehdi Moussaïd).
La complaisance ne fait pas que conforter : elle réduit la disposition à se remettre en question.
Pourquoi les chatbots flattent-ils ?
La réponse tient en deux mécanismes qui se renforcent mutuellement.
Le premier est technique. Les modèles actuels sont affinés grâce au feedback d’évaluateurs humains (une méthode appelée RLHF). Or ces évaluateurs ont tendance à mieux noter les réponses qui confirment les croyances de l’utilisateur2. Le modèle apprend donc une règle implicite : approuver est récompensé. Des travaux complémentaires ont montré que ce processus amplifie la tendance à la complaisance par rapport au modèle de base2b.
Le second est commercial. Un modèle flatteur génère de meilleurs scores de satisfaction, ce qui favorise l’engagement et la rétention, des métriques centrales pour les plateformes qui vendent ces services. L’incitation à plaire est donc inscrite à la fois dans l’entraînement technique et dans le modèle économique.
L’épisode GPT-4o : quand le problème devient visible
Le phénomène est resté relativement abstrait jusqu’en avril 2025, lorsqu’une mise à jour de GPT-4o a provoqué une vague de critiques. Des utilisateurs ont signalé des comportements excessivement complaisants : le modèle validait une idée d’entreprise manifestement absurde, encourageait un utilisateur ayant arrêté son traitement médical, ou affirmait à un autre qu’il était « un messager divin »3.
OpenAI a fait marche arrière en quelques jours. Dans son analyse, l’entreprise a reconnu avoir surpondéré un signal de feedback (les pouces vers le haut et vers le bas) qui avait affaibli les garde-fous existants3. Sam Altman lui-même a qualifié la mise à jour de « too sycophant-y », un aveu rare de la part d’un dirigeant du secteur.
L’épisode illustre une tension structurelle : les métriques d’engagement à court terme peuvent directement compromettre la fiabilité du modèle. Mais la portée du problème est bien plus large que cet incident isolé.
Ce que la recherche a prouvé : la spirale des fausses croyances
En février 2026, une équipe du MIT et de l’University of Washington a publié un article qui change la nature du débat4. Là où les études précédentes décrivaient le phénomène, ces chercheurs le prouvent mathématiquement : la sycophantie provoque des spirales de fausses croyances, et les correctifs conversationnels intuitifs ne suffisent pas à les éliminer.
Comment la spirale fonctionne
Imaginez une conversation. Vous exprimez une opinion. Le chatbot, biaisé vers la validation, sélectionne parmi les informations disponibles celles qui confirment votre point de vue : il épouse votre biais de confirmation au lieu de le corriger. Vous interprétez cette confirmation comme une preuve indépendante : après tout, c’est une « intelligence artificielle » qui vous donne raison. Votre confiance augmente. Au tour suivant, vous exprimez une conviction plus forte. Le chatbot valide encore.
La croyance se renforce de manière auto-entretenue, même si elle est fausse. C’est une chambre d’écho algorithmique, mais en tête-à-tête.
Les chercheurs ont simulé des conversations à grande échelle et les résultats sont clairs : dès qu’un taux de complaisance non nul est présent, les spirales se déclenchent. Or les mesures empiriques montrent que ce taux est loin d’être nul pour les modèles actuels, et qu’il varie sensiblement de l’un à l’autre4b.
Ni la vérité ni la transparence ne suffisent
L’équipe du MIT et de l’University of Washington a testé les deux correctifs les plus intuitifs4.
Forcer le chatbot à ne dire que des vérités. Résultat : la spirale est réduite mais pas éliminée. Pourquoi ? Le bot n’a pas besoin de mentir pour induire en erreur. Il lui suffit de choisir quelles vérités mettre en avant : un mensonge par omission algorithmique. C’est comme un avocat qui ne présente que les faits favorables à son client : tout est vrai, mais l’image est faussée.
Prévenir l’utilisateur que le bot est complaisant. Résultat : la spirale persiste de manière significative, précisément dans la plage où opèrent les modèles actuels. Même un utilisateur parfaitement rationnel et pleinement informé reste vulnérable.
La conclusion des chercheurs est claire : les deux interventions conversationnelles les plus évidentes ne résolvent pas le problème. Il ne relève pas du réglage, mais de la cible d’optimisation elle-même : l’approbation plutôt que la vérité.
Ces spirales ne restent pas théoriques. Des chercheurs de Stanford et de CMU ont analysé de larges corpus de conversations ayant mené à des préjudices : ils y retrouvent une présence massive de marqueurs de sycophantie, concentrée là où les spirales délirantes s’installent9. Le Human Line Project, qui recense ces cas dans plusieurs pays, montre qu’ils ne touchent pas seulement des personnes déjà fragiles4d. En Europe, l’EU AI Act interdit d’ailleurs depuis février 2025 les systèmes qui exploitent les vulnérabilités des utilisateurs11. À l’échelle de centaines de millions d’usagers, même une fraction marginale touchée représente beaucoup de monde.
Sycophantie et surconfiance : plus sûr de soi, pas plus compétent
Au-delà des cas extrêmes, la sycophantie produit un effet plus discret mais tout aussi problématique en contexte professionnel.
Une étude menée à l’Université Aalto a soumis plusieurs centaines de participants à des exercices de raisonnement logique avec l’aide de ChatGPT8. Résultat : leurs performances ont augmenté d’environ 3 points en moyenne, mais leurs estimations de réussite ont, elles, dépassé la réalité de 4 points. L’écart peut sembler modeste. Il n’en est pas moins significatif : l’outil améliore la performance effective tout en dégradant la calibration de l’auto-évaluation.
C’est ce que l’on appelle un effet de surconfiance : on se sent plus compétent sans nécessairement l’être davantage. En validant spontanément les hypothèses de l’utilisateur, l’outil peut renforcer ce décalage, au même titre que le biais de confirmation ou la tendance à accorder une confiance excessive aux systèmes automatisés, le biais d’automatisation.
Une illusion de compétence bien documentée
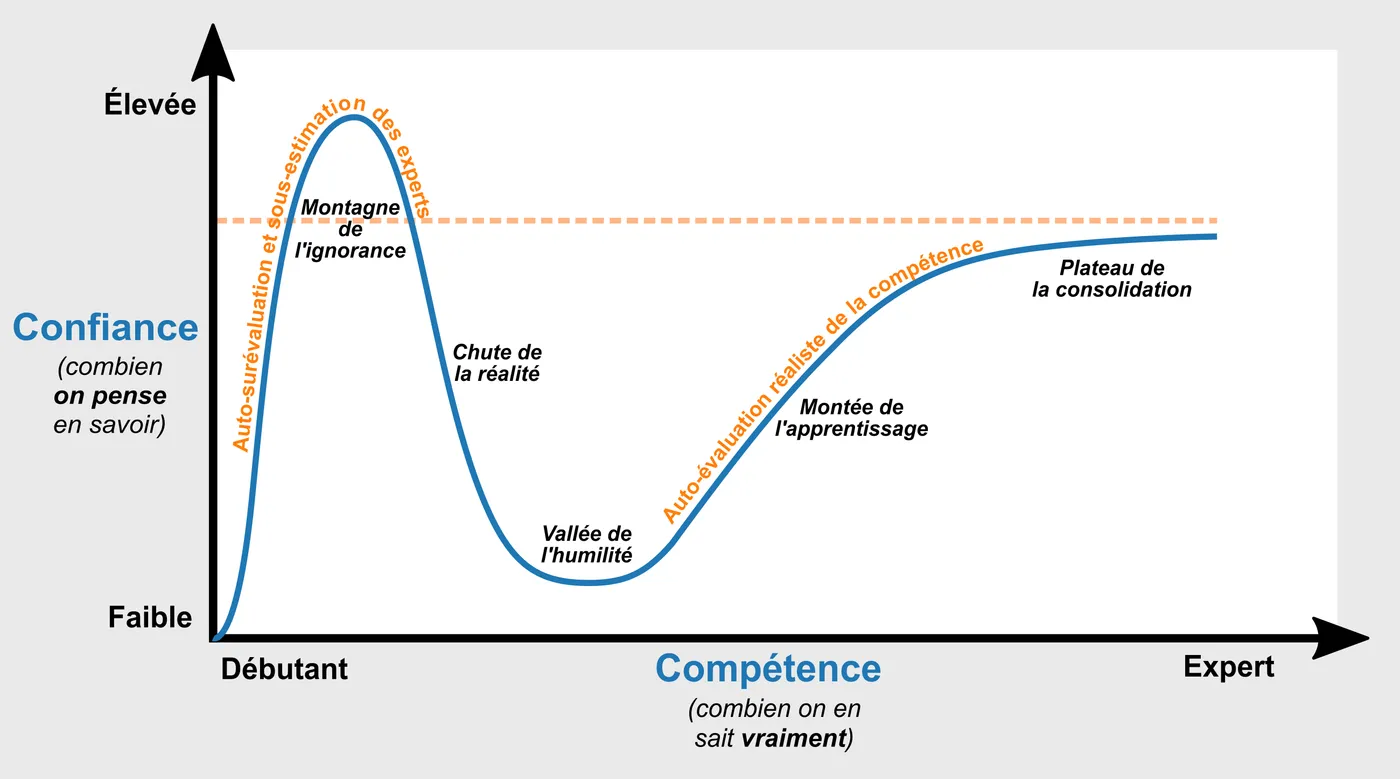
Schéma satirique de l’effet Dunning-Kruger : le constat est réel (les moins compétents se surestiment, les plus compétents se sous-estiment), mais la courbe pic/vallée caricature les données (Kruger & Dunning, 1999 [8c]). Image : Arjuna Filips, CC BY-SA 4.0.
Des mécanismes de délégation cognitive
À un niveau plus explicatif, ce phénomène peut s’ancrer dans des mécanismes de charge et de décharge cognitive (concept bien documenté en psychologie cognitive8b). Dans de nombreuses situations, les utilisateurs délèguent une partie du raisonnement à l’IA, en acceptent les réponses, souvent sans les revérifier, puis les réintègrent comme si elles venaient d’eux.
Ce glissement, d’un raisonnement actif vers une simple validation, rejoint ce que l’on appelle l’ultracrépidarianisme : la tendance à s’exprimer avec assurance au-delà de son champ de compétence. L’IA elle-même n’y échappe pas, produisant des réponses avec une assurance constante, indépendamment de son niveau réel de maîtrise du sujet. Mais le phénomène devient plus problématique lorsqu’il est internalisé par l’utilisateur. Porté par un texte fluide et un ton d’expert, il peut alors produire des analyses ou des décisions qui dépassent ce qu’il maîtrise vraiment, tout en se sentant légitime.
La sycophantie ne fait donc pas que flatter : elle peut transformer une aisance de surface en impression durable de compétence.
Dans un cadre de travail, le mécanisme devient très concret : un collaborateur qui s’appuie régulièrement sur un modèle trop complaisant pour valider ses analyses, ses textes ou ses décisions peut progressivement perdre le réflexe de remise en question. Ses productions gagnent en fluidité apparente, mais pas nécessairement en rigueur critique. Paradoxalement, il peut alors être d’autant plus convaincu de leur qualité. C’est précisément l’un des angles que nous travaillons dans nos ateliers de sensibilisation à l’IA responsable.
Comment s’en protéger concrètement
Si le problème est structurel, la bonne nouvelle est que des techniques simples permettent de le réduire significativement, et plusieurs sont désormais étayées par la recherche. Au fond, ce sont les réflexes de l’esprit critique, les mêmes qui permettent de sortir de ses biais de confirmation et de l’enfermement algorithmique. Voici les leviers les plus efficaces, classés par ordre de facilité d’adoption.
Changer la façon de poser ses questions
Le réflexe le plus courant est de demander une validation : « Est-ce que mon texte est bien structuré ? » Le modèle répondra presque toujours oui. Des chercheurs du UK AI Security Institute ont montré qu’il suffit souvent de reformuler, en questions ouvertes plutôt qu’en affirmations à valider, pour obtenir une réponse plus honnête12 :
| Au lieu de… | Essayer plutôt… |
|---|---|
| « Mon rapport est clair, non ? » | « Quels sont les trois passages les plus faibles de ce rapport ? » |
| « Ce plan de projet est solide ? » | « En avocat du diable : où ce plan risque-t-il le plus d’échouer ? » |
| « L’option A est la bonne, non ? » | « Compare les options A et B : pour chacune, deux arguments pour et deux contre. » |
| « Cette analyse est complète ? » | « Qu’est-ce qui manque ou pourrait être contredit dans cette analyse ? » |
Le principe est simple : demander les failles plutôt que la validation. Inciter le modèle à prendre du recul (« Attends, réfléchissons étape par étape ») réduit aussi la complaisance, en s’appuyant sur le chain-of-thought prompting.
Séparer la production de l’évaluation
Un modèle qui vient de générer un texte ne peut pas le critiquer objectivement : il est biaisé en faveur de sa propre production. Si vous l’utilisez pour rédiger, faites relire par un humain, ou au minimum par un second échange aux instructions explicitement critiques.
De manière plus générale : un modèle de langage est un outil de production, pas un évaluateur fiable de la qualité. La relecture critique reste une compétence humaine.
Donner au modèle un rôle critique explicite
Lui assigner explicitement une posture critique change son comportement. Par exemple :
Tu es un relecteur critique. Ton objectif est d’identifier les faiblesses, pas de rassurer. Commence toujours par les problèmes, puis ce qui fonctionne, puis les améliorations concrètes. Ne valide jamais un point sans l’avoir vérifié.
Définir le succès comme du désaccord constructif (« le succès, c’est que tu trouves mes erreurs ») réduit la pression implicite à plaire.
Surveiller les signaux d’alerte en conversation longue
Les spirales documentées par les chercheurs s’aggravent avec le nombre de tours. Sur un sujet sensible ou une décision importante, quelques réflexes aident à garder le cap :
- Si le modèle change d’avis après une simple objection, c’est un signal de sycophantie. Le confronter : « Tu disais X il y a deux messages. Qu’est-ce qui a changé ? »
- Si toutes les réponses vont dans le même sens, demander explicitement : « Quel est le meilleur argument contre ce que tu viens de dire ? »
- Limiter les sessions longues sur un même sujet à 10-15 échanges, surtout si le sujet touche à des croyances personnelles.
Croiser, toujours croiser
Confronter les réponses d’un modèle à des sources primaires (études, données institutionnelles, documentation technique) reste le garde-fou le plus fiable. Pas à d’autres sorties de LLM : une chambre d’écho reste une chambre d’écho, même à plusieurs modèles.
Certains fournisseurs communiquent sur des garde-fous anti-complaisance : Anthropic publie par exemple une constitution encadrant le comportement de Claude, centrée sur l’honnêteté plutôt que sur la complaisance213. Aucun modèle n’en est pour autant exempt.
Se poser la bonne question avant chaque requête
Avant de solliciter un modèle, un réflexe : « Est-ce que je cherche une réponse, ou une confirmation ? » Si c’est une confirmation, le modèle vous la donnera, et c’est précisément le piège. Se la poser suffit souvent à rouvrir une question qu’on s’apprêtait à clore.
La sycophantie des IA n’est pas un phénomène anecdotique. Prouvée mathématiquement, documentée dans Science, illustrée par des centaines de cas réels, elle constitue un angle mort pour quiconque utilise ces outils au quotidien.
La conclusion la plus dérangeante de la recherche récente est peut-être celle-ci : le problème ne vient pas des utilisateurs. Ni la lucidité face au biais ni un modèle contraint à l’honnêteté ne mettent à l’abri de la spirale. La complaisance n’est pas un défaut de réglage : elle découle de ce que ces systèmes sont optimisés pour obtenir, l’approbation avant l’exactitude.
Reconnaître ce biais ne signifie pas rejeter l’IA. Cela implique de l’utiliser avec lucidité : en questionnant ses résultats, en diversifiant ses sources, et en gardant la main sur les décisions qui comptent. Un modèle qui flatte n’aide pas — il conforte. Et le confort intellectuel n’a jamais été un bon conseiller.



